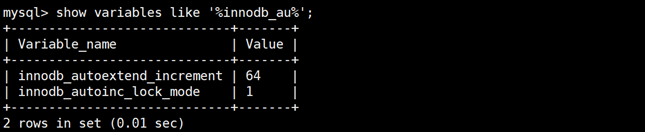
数据日志文件比对
ib_logfile与log-bin区别
| ib_logfile |
记录系统的回滚,重做日志(在你修改数据之前,会先把 修改的操作 作为日志先记录下来) 记录文件的物理更改 记录的是redo log和undo log(应该记录在ibdata1中)的信息,这里记录的基本是commit之前的数据 |
| mysql-bin.****** |
记录系统的所有更新记录,数据库的更细日志,记录的是逻辑更改 主从:mysql会把日志发送到slave,salve会接收日志,然后解析日志,把里面的sql语句重新应用到数据库里,于是就能同步数据了 记录的是已经执行完毕的对数据库的dml和ddl信息,这里记录的基本是commit之后的数据信息。 |
redo、undo、binlog的区别
| redo | undo | binlog | |
|---|---|---|---|
| 作用 | 保持事务的持久性 | 帮助事务回滚及MVCC的功能 | 进行Point-In_Time的恢复及主从复制的建立 |
| 产生主体 | InnoDB | MySql | MySql |
| 类型 | 物理日志,只记录有关InnoDB引擎本身的事务日志。 | 逻辑日志 |
记录的都是关于一个事务的具体操作内容,逻辑日志。 记录所有与MySQL数据库有关的日志记录,包括InnoDB、MyISAM、Heap等其他存储引擎的日志。 |
| 内容 | 每个页的修改,重做日志主要是记录已经全部完成的事务,即执行了commit的日志,在默认情况下重做日志的值记录在iblogfile0 以及iblogfile1重做日志中。 | 修改前的行数据,回滚日志主要记录已经部分完成并且写入硬盘的未完成事务,默认情况情况下,回滚日志的信息记录在表空间文件,共享表空间文件ibdata1或者独享表空间未见ibd中。 | 执行的SQL语句 |
| 每个事务的日志数量 | 事务执行中不断写入,多事务可并发写入 | 看修改的行数据量 | 事务提交后记录一条SQL语句,根据配置执行 |
| 幂等性 | 是 | 否 | |
| 日志文件 | ib_logfile | Ibdata | mysql-bin.****** |
| 事务性 | INNODB存储引擎的重做日志,由于其记录是物理操作日志,因此每个事务对应多个日志条目,并且事务的重做日志写入是并发的,并非在事务提交时写入,做其在文件中记录的顺序并非是事务开始的顺序。 | 二进制日志仅在事务提交时记录,并且对于每一个事务,仅在事务提交时记录,并且对于每一个事务,仅包含对应事务的一个日志。 |
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志(但是可以设置清理策略)。
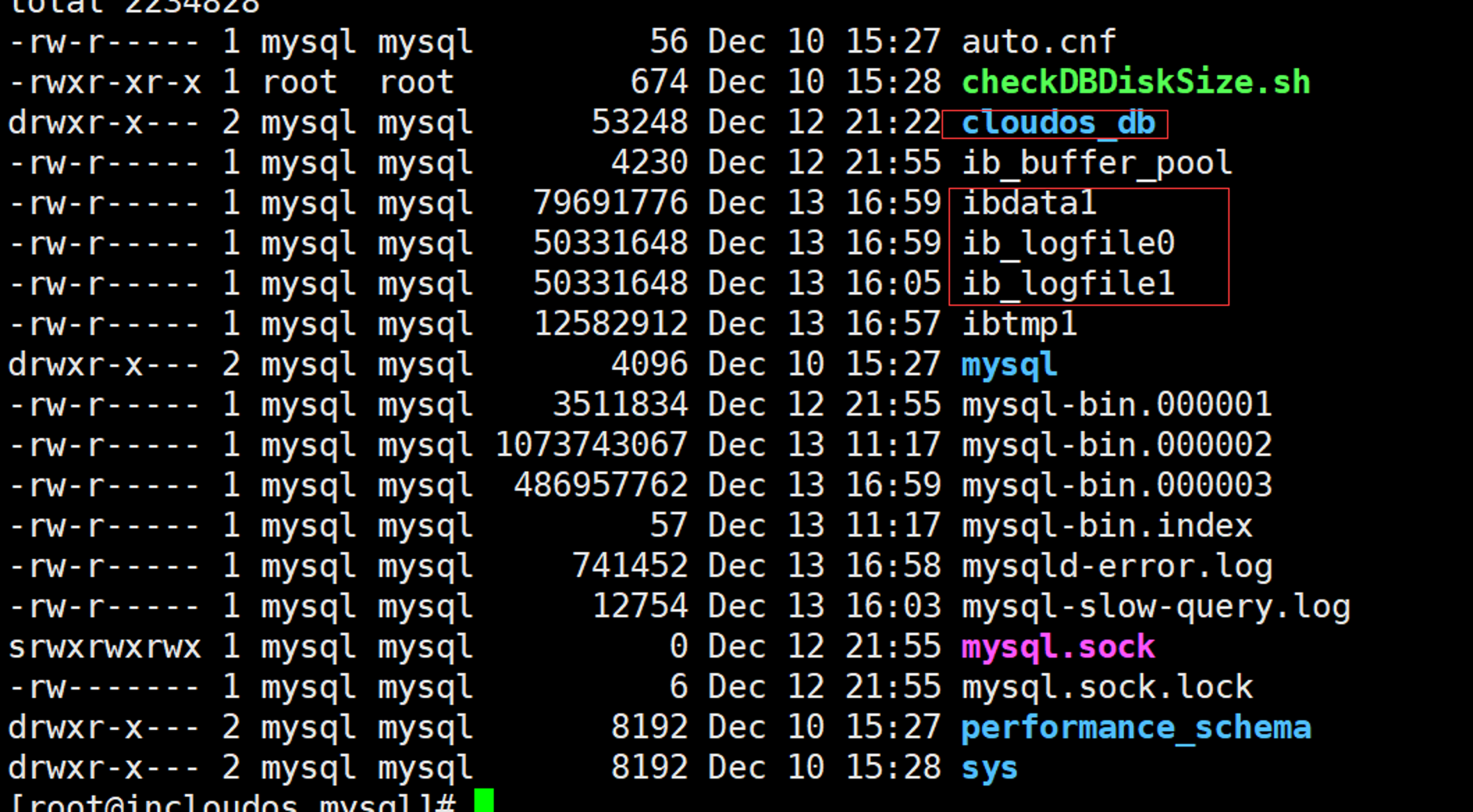
ibdata
作用
ibdata1是一个用来构建innodb系统表空间的文件,这个文件包含了innodb表的元数据(数据字典)、
撤销记录(FIL_PAGE_UNDO_LOG)****出现问题的可能性比较大、
修改buffer(innodb_ibuf_max_size 设置最大变更缓冲区
双写buffer(innodb_doublewrite_file 来将双写缓冲区存储到一个分离的文件)
如果file-per-table选项打开的话,该文件则不一定包含所有表的数据。当innodb_file_per_table选项打开的话,新创建表的数据和索引则不会存在系统表空间中,而是存放在各自表的.ibd文件中。
使用命令:SHOW ENGINE INNODB STATUS \g;查看当前二进制的状态。
显然这个文件会越来越大,innodb_autoextend_increment选项则指定了该文件每次自动增长的步进,默认是8M。
导致该文件变大的原因
显然ibdata文件存的是数据库的表数据,如缓存,索引等。所以随着数据库越来越大,表也会越大,这个无法避免的。
瘦身
- 按照类型分类
- 数据文件与日志信息分文件保存,对于日志文件可以定期执行清理。
- 或者定期数据备份和恢复
- 先把数据库文件备份下来,然后直接删除ibdata文件,重新导入数据库文件即可。这样就可以把ibdata中的日志和缓存都删除掉了。
1 | # 备份全部数据库,执行命令 |
删除原数据文件后
扩容
为了添加一个数据文件到表空间中,首先要关闭 MySQL 数据库,编辑 my.cnf 文件,确认innodb ibdata文件的实际情况和my.cnf的配置是否一致,这里有两种情况:
- my.cnf的配置
innodb_data_file_path=ibdata1:10G;ibdata2:10G:autoextend
如果当前数据库正在使用ibdata1,或者使用ibdata2,但ibdata2没有超过10G,则对my.cnf配置直接改成:innodb_data_file_path=ibdata1:10G;ibdata2:10G;ibdata3:10G:autoextend - 如果设置了最后一个ibdata自动扩展时,有可能最后一个ibdata的占用空间大于my.cnf的配置空间。例如:
1 | mysql@test:/data1/mysqldata/innodb/data> ls -lh |
这时,需要精确的计算ibdata2的大小 15360M,修改:
innodb_data_file_path=ibdata1:10G;ibdata2:15360M;ibdata3:10G:autoextend
重启mysql。
注意:
1、扩容前注意磁盘空间是否足够。
2、restart后关注是否生成了新的ibdata。
更多说明
如果,最后一个文件以关键字 autoextend 来描述,那么编辑 my.cnf 的过程中,必须检查最后一个文件的尺寸,并使它向下接近于 1024 * 1024 bytes (= 1 MB) 的倍数(比方说现在autoextend 的/ibdata/ibdata1为18.5M,而在旧的my.ini中为10M,则需要修改为innodb_data_file_path = /ibdata/ibdata1:19M; 且必须是19M,如果指定20M,就会报错。),并在 innodb_data_file_path 中明确指定它的尺寸。然后你可以添加另一个数据文件。记住只有 innodb_data_file_path 中的最后一个文件可以被指定为 auto-extending。
一个例子:假设起先仅仅只有一个 auto-extending 数据文件 ibdata1 ,这个文件接近于 988 MB。下面是添加了另一个 auto-extending 数据文件后的可能示例 。
1 | innodb_data_home_dir = |
日志分析工具
- mysqldumpslowmysql:官方提供的慢查询日志分析工具
- mysqlsla:hackmysql.com 推出的一款日志分析工具(该网站还维护了 mysqlreport,mysqlidxchk 等比较实用的mysql 工具)。 整体来说,功能非常强大。输出的数据报表非常有利于分析慢查询的原因,包括执行频率、数据量、查询消耗等。
- myprofi:纯 php 写的一个开源分析工具.项目在 sourceforge 上。功能上,列出了总的慢查询次数和类型、去重后的 sql 语句、执行次数及其占总的 slow log 数量的百分比。从整体输出样式来看,比 mysql-log-filter 还要简洁,省去了很多不必要的内容。对于只想看 sql 语句及执行次数的用户来说,比较推荐。
- mysql-log-filter:google code 上找到的一个分析工具,提供了 python 和 php 两种可执行的脚本。 特色功能除了统计信息外,还针对输出内容做了排版和格式化,保证整体输出的简洁。喜欢简洁报表的朋友,推荐使用一下。
其他
主从不一致
在m/s环境中,innodb写完ib_logfile后,服务异常关闭,会不会主库能用ib_logfile恢复数据,而
binlog没写导致从库同步时少少这个事务?从而导致主从不一致;
redo日志写入方式
- ib_logfile写入当前事务更新数据,并标上事务准备trx_prepare
- 写入bin-log
- ib_logfile当前事务提交提交trx_commit
恢复方式
如果ib_logfile已经写入事务准备,那么在恢复过程中,会依据bin-log中该事务是否存在恢复数据。
假设:
- 结束后异常,因没有写入bin-log,从库不会同步这个事务,主库上,重启时,在恢复日志中这个事务没有commit,即rollback这个事务.
- 结束后异常,这会bin-log已经写入,从库会同步这个事务。主库依据恢复日志和bin-log,也正常恢复此事务
综上描述:bin-log写入完成,主从会正常完成事务;bin-log没有写入,主从库rollback事务;不会出现主从库不一致问题.
日志文件备份
备份的时候可以使用flush logs,关闭当前的所有日志文件,然后产生新的日志文件。关闭日志文件后,可以采用物理方式备份。 另外flush logs可以添加具体的日志类型:
- flush error logs
- flush general logs
- flush binary logs
- flush slow logs
Checkpoint机制
MySQL服务器崩溃后,重新启动MySQL服务时,由于重做日志(redo)与回滚日志(undo)日志的存在,InnoDB通过回滚日志(undo)日志将所有已部分完成并写入硬盘的未完成事务进行回滚操作(rollback)。然后将重做日志(redo)日志中的事务全部重新执行一遍即可恢复所有的数据。但是数据量过大,为了缩短恢复的时间InnoDB引入了Checkpoint 机制。
Checkpoint 机制原理
假设在某个时间点,所有的脏页(dirty page)都被刷新到了硬盘上,这个时间点之前的所有重做日志(redo)就不需要重做了.系统就就下这个时间点重做日志的结尾位置作为Checkpoint,Checkpoint之前的重做日志也就不需要再重做了,可以放心的删除掉。为了更好的利用重做日志(redo)的空间,InnoDb采用轮循的策略使用重做日志空间,因此InnoDB的重做日志文件至少为2个。通过Checkpoint 机制,通过重做日志(redo)将数据库崩溃时已经完成但还没有来得及将缓存中已经修改但还未完全写入外存的事务进行重做(undo)操作,即可保证数据的一致性,也可以缩短恢复时间。
脏页(dirty page)
当事务需要修改某条记录是,InnoDB首先将该数据所在的数据块从外存中读取到硬盘中,事务提交后,InnoDB修改数据页中的记录,这时缓存的数据页已经和外存中的数据块已经不一样了,此时缓存中的数据页称为脏页(dirty page),脏页刷新到外存中,变为干净页(clean page)。
备注:一个内存页默认为4K,或者4K的倍数。你可以把内存想象成一本可以擦洗的书,每次MySQL读数据的时候,向内存申请几张干净的书页,然后书写上去。当数据刷新到硬盘之后,这些数据页马上被擦除,供其他程序使用。
日志序列号(log sequence number)
日志序列号(LSN)是日志空间中每条日志的结束点,用字节偏移量表示,在Checkpoin和恢复时使用。

