安装模式
单机模式
安装简单,几乎不用作任何配置,但仅限于调试用途;
伪分布模式
在单节点上同时启动NameNode、DataNode、JobTracker、TaskTracker、Secondary Namenode等5个进程,模拟分布式运行的各个节点;
完全分布式模式
正常的Hadoop集群,由多个各司其职的节点构成
实验环境
创建安装用户(sunld),所有的组件和jdk放到目前/app下,并且授权如下:
chown –R sunld:sunld /app
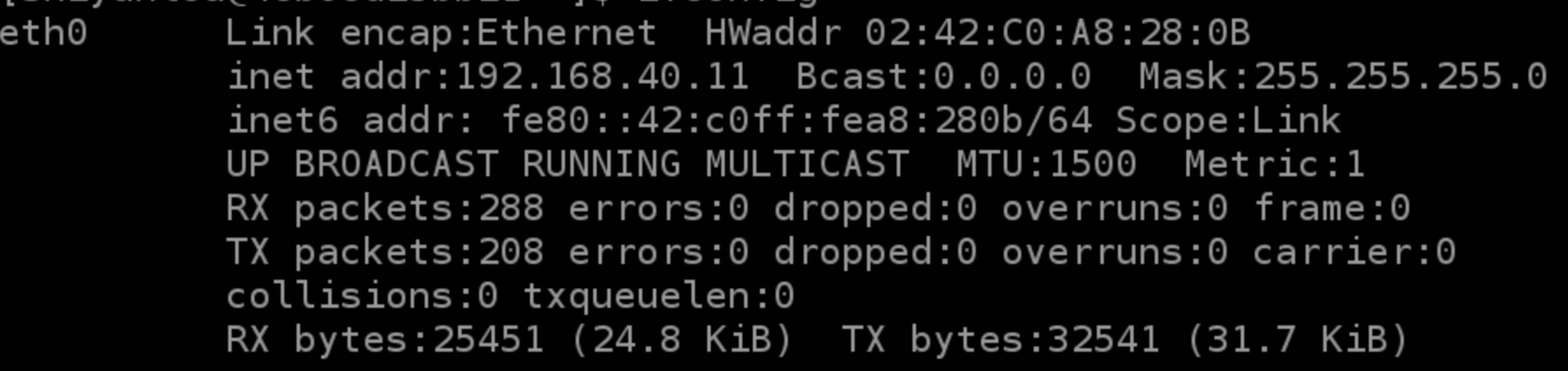
设置网络
IP地址: 192.168.42.8
子网掩码: 255.255.255.0
DNS: 221.12.1.227 (需要根据所在地设置DNS服务器)
Domain: 221.12.33.227
效果如下:
设置机器名(重启后生效)
设置host映射文件
使用ping命令验证配置是否正确
关闭防火墙
1
2
| sudo service iptables status
sudo chkconfig iptables off
|
关闭Selinux
- 使用getenforce命令查看是否关闭
- 修改/etc/selinux/config 文件
将SELINUX=enforcing改为SELINUX=disabled,执行该命令后重启机器生效
安装jdk
首先在官网现在安装包,创建安装目录,如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
| sudo mkdir /app
sudo chown -R sunld:sunld /app
mkdir /app/lib
tar -zxf jdk-7u55-linux-x64.tar.gz
mv jdk1.7.0_55/ /app/lib
ll /app/lib
配置环境变量:sudo vi /etc/profile
export JAVA_HOME=/app/lib/jdk1.7.0_55
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
|
验证
1
2
| source /etc/profile
java -version
|
更新OpenSSL
SSH无密码验证配置
- 使用sudo vi /etc/ssh/sshd_config,打开sshd_config配置文件,开放三个配置
- RSAAuthentication yes
- PubkeyAuthentication yes
- AuthorizedKeysFile .ssh/authorized_keys
- 配置后重启服务:sudo service sshd restart
- 使用shiyanlou用户登录使用如下命令生成私钥和公钥;ssh-keygen -t rsa

- 进入/home/shiyanlou/.ssh目录把公钥命名为authorized_keys,使用命令如下:cp id_rsa.pub authorized_keys
- 使用如下设置authorized_keys读写权限:sudo chmod 400 authorized_keys
- 测试ssh免密码登录是否生效
Hadoop变量配置
下载安装包
1
2
3
| tar -xzf hadoop-1.1.2-bin.tar.gz
rm -rf /app/hadoop-1.1.2
mv hadoop-1.1.2 /app
|
创建子目录
1
2
3
4
5
6
| cd /app/hadoop-1.1.2
mkdir tmp
mkdir hdfs
mkdir hdfs/name
mkdir hdfs/data
ls
|
把hdfs/data设置为755,否则DataNode会启动失败
chmod -R 755 data
配置hadoop-env.sh
- 进入hadoop-1.1.2/conf目录,打开配置文件hadoop-env.sh
1
2
| cd /app/hadoop-1.1.2/conf
vi hadoop-env.sh
|
- 加入配置内容,设置了hadoop中jdk和hadoop/bin路径
1
2
| export JAVA_HOME=/usr/lib/java/jdk1.7.0_55
export PATH=$PATH:/app/hadoop-1.1.2/bin
|
- 编译配置文件hadoop-env.sh,并确认生效
1
2
| source hadoop-env.sh
hadoop version
|
配置core-site.xml
1
2
3
4
5
6
7
8
9
10
| <configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop-1.1.2/tmp</value>
</property>
</configuration>
|
配置hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/app/hadoop-1.1.2/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/app/hadoop-1.1.2/hdfs/data</value>
</property>
</configuration>
|
配置mapred-site.xml
1
2
3
4
5
6
| <configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop:9001</value>
</property>
</configuration>
|
配置masters和slaves文件
- vi masters
- vi slaves
- 输入hadoop(节点名称)
格式化namenode
在hadoop1机器上使用如下命令进行格式化namenode
hadoop namenode -format
启动hadoop
1
2
| cd /app/hadoop-1.1.2/bin
./start-all.sh
|
用jps检验各后台进程是否成功启动